In this post, I will try to explain how a program is actually laid out in main memory for being executed.
Here, I am assuming the program to be run on a multitasking Linux OS hosted on a 32-bit x86 architecture, in fact some of the details discussed below may be slightly different on other systems.
Each process in a multitasking OS runs in its own memory sandbox. This is the virtual address space, which in case of a 32-bit system is always a 4GB block of memory addresses. Indeed, since the smallest unit addressable by the CPU is 1 byte = 8 bit, it turns out that a 32-bit CPU is able to generate up to 2^32 – 1 “numbers”, i.e., addresses each one pointing to a specific byte in memory. These virtual addresses (generated by the CPU) are then mapped to real, physical memory addresses by page tables, which are kept by the operating system kernel. Since the OS kernel is a process itself, it has a dedicated portion of the virtual address space. This is separated from the portion reserved for any other user’s application processes (i.e., not OS processes). For instance, the first 3 GB of virtual addresses (i.e., from 0x00000000 to 0xBFFFFFFF) can be used for user processes while the last 1 GB of virtual addresses (i.e., from 0xC0000000 to 0xFFFFFFFF) are reserved to the OS kernel.
The following picture shows a possible split between OS kernel and user mode virtual memory spaces on a typical 32-bit Linux OS.

Please, refer to the post on Virtual Memory, Paging, and Swapping where I discuss better on this.
Coming back to our main subject, the picture below shows how a program looks like in main memory, in fact how a process looks like within the User Mode portion of the virtual address space! Let us inspect each memory segment, independently.
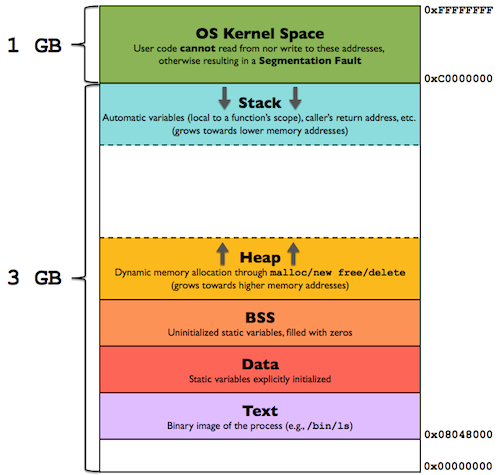
– Text: Text segment, also known as a Code segment, is the section of memory which contains executable instructions of a program. It may be placed below the Heap or Stack in order to prevent overflows from overwriting it.
Usually, the text segment is sharable so that only a single copy needs to be in memory for frequently executed programs, such as text editors, the C compiler, the shells, and so on.
Finally, the text segment is often Read-only/Execute to prevent a program from accidentally modifying its instructions.
– Data: Data segment is a shorthand for “Initialized data segment”.
This portion of the virtual address space of a program contains the global and static variables that are initialized by the programmer.
Generally speaking, the data segment is not Read-only, since the values of the variables can be altered at run time. In fact, it can be further classified into initialized Read-only area (i.e., RoData) and initialized Read-Write area.
For instance, the following C statements outside the main (i.e., global)
char s[] = "hello world";
int debug = 1;
would be stored in initialized Read-Write area.
On the other hand, a C statement like the following
const char* str = "hello world";
defines a character pointer variable (identified by str), which points to the first char of the constant string literal "hello world". In such a case, the string literal "hello world" is stored in initialized Read-only area while the character pointer variable str in initialized Read-Write area (because it may actually be modified at run-time). Similarly, static int i = 10; will also be stored in the Read-Write area of the data segment.
– BSS: BSS segment also refers to “Uninitialized data segment”, and it is named so after an ancient assembler operator that stood for “Block Started by Symbol”. Data in this segment is initialized by the OS kernel to arithmetic 0 before the program starts executing.
Typically, this segment starts at the end of the data segment and contains all global and static variables that are initialized to zero or do not have explicit initialization in source code. For instance, a variable declared as static int i; would be allocated to the BSS segment.
Finally, the BSS segment is Read-Write.
– Stack: The Stack area contains the program stack, i.e., a LIFO structure typically located in the higher memory addresses right below the OS kernel space (except for a constant offset called Random Stack Offset). On the standard x86 architecture it grows downwards to lower addresses, (i.e., as opposed to the adjacent Heap area which instead grows upwards) but on some other architectures it may grow the opposite direction.
This area is devoted to store all the data needed by a function call in a program. Specifically, the set of values pushed for one function call is named a stack frame, and consists of all the automatic variables (i.e., local to the scope of the function’s body and including any actual parameters passed as input to the function) and the caller’s return address. This is exactly how recursive functions are implemented in C: each time a recursive function calls itself, a new stack frame is allocated on top of the stack, thus the set of variables within one call are completely independent from those of another function call.
A stack pointer register tracks the top of the stack (i.e., how much of the stack area the process is currently using), and it is adjusted each time a value is “pushed” onto the stack. If the stack pointer meets the heap pointer (or if it eventually reaches the limit posed by RLIMIT_STACK), the available free memory is exhausted.
– Heap: Heap is the segment where dynamic memory allocation usually takes place, i.e., to allocate memory requested by the programmer for variables whose size can be only known at run-time and cannot be statically determined by the compiler before program execution. The heap area begins at the end of the BSS segment and grows upwards to higher memory addresses. It is managed by malloc/new, free/delete, which may use the brk and sbrk system calls to adjust its size.
This area is shared by all shared libraries and dynamically loaded modules in a process.

Superb Explanation of Concept
Thanks for the recursion explanation!!