Any statistic over a population of items (e.g., the population mean 
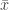
Without loss of generality, suppose we are interested in estimating the true, yet unknown, statistic 

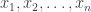
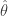
From the Central Limit Theorem (CLT) we know that, no matter what is the underlying distribution governing the population, any statistic computed from repeated samples drawn from that population will approach a Normal distribution, as the sample size goes to infinity, i.e. as 

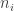
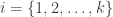

The distribution of such sample statistics is usually referred to as the sampling distribution (of the sample statistic). Under the assumption made by the CLT (i.e. as the sample size goes to infinity) the sampling distribution approaches a Normal distribution. Indeed, if we plot the frequency histogram of the values of those sample statistics
In fact, by repeating the sampling estimate multiple times (i.e. 
As already said, the CLT guarantees the result above for any statistic, in particular this is true for the population mean (
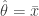
Coming back to our original question, we may be interested in evaluating how close/far our estimated sample statistic is with respect to the true statistic.
A confidence interval gives an estimated range of values, instead of a simple single-point estimate, which is likely to include an unknown population parameter; the estimated range is calculated from a given set of sample data.
Together with the confidence interval comes the confidence level, which describes the uncertainty associated with a sampling method. Suppose we use the same sampling method to select different samples and to compute a different interval estimate for each sample. Some interval estimates would include the true population parameter and some would not. Therefore, a 0.90 confidence level (i.e. 90%) means that we would expect 90% of the interval estimates to include the population parameter; A 0.95 confidence level means that 95% of the intervals would include the parameter; and so on.
Note that this is fundamentally different from saying that a 90% confidence interval indicates that there exists a 90% chance of the true population statistic falling in that interval. In fact, any population statistic is not a random variable yet it is a constant. Therefore, given any interval, the probability of the population statistic being in that interval is either 0 (if the constant does not fall in that range) or 1 (if it does).
To fully express a confidence interval, one needs three pieces of information:
- Confidence level
where
usually denotes the significance level;
- Sample statistic
- Margin of error
.
Intuitively, we want to give an upper bound to the error
Putting all together, the confidence interval 
The uncertainty associated with the confidence interval 

![C = [\hat{\theta} - \epsilon, \hat{\theta} + \epsilon]](https://s0.wp.com/latex.php?latex=C+%3D+%5B%5Chat%7B%5Ctheta%7D+-+%5Cepsilon%2C+%5Chat%7B%5Ctheta%7D+%2B+%5Cepsilon%5D&bg=ffffff&fg=333333&s=2&c=20201002)
How to Construct a Confidence Interval
There are 4 steps to constructing a confidence interval.
1) Choose a sample statistic of interest
2) Select a confidence level 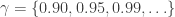
3) Find the margin of error
where 






How to find the Critical Value
The critical value is a factor used to compute the margin of error. We describe how to find such critical value, when the sampling distribution of the sample statistic is Normal or quasi-Normal.
Remember that the Central Limit Theorem states that the sampling distribution of any sample statistic will be Normal or nearly Normal, if any of the following conditions apply:
- The population distribution is Normal;
- The sampling distribution is symmetric, unimodal, without outliers, and the sample size is 15 or less;
- The sampling distribution is moderately skewed, unimodal, without outliers, and the sample size is between 16 and 40;
- The sample size is greater than 40, without outliers.
When one of these conditions is satisfied, the critical value can be expressed as a z-score or as a t-score. To find the critical value, follow these steps.
– Compute 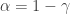
– Find the critical probability value 
Then, to express the critical value as a z-score, find the value 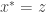




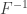
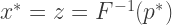

If we want to express the critical value as a t-score, instead, the following steps are needed:
– Find the degrees of freedom (DF). When estimating a population mean or a proportion from a single sample, DF is equal to the sample size minus one. For other applications, the degrees of freedom may be calculated differently.
The critical t-score 
Should one express the critical value as a z-score or as a t-score? There are several ways to answer this question. As a practical matter, when the sample size is large (greater than 40), it doesn’t make much difference. Both approaches yield similar results. Strictly speaking, when the standard deviation of the population
4) Specify the confidence interval
Finally, the intuition behind confidence interval is very much related to the idea of hypothesis testing, which we explore in another article.
